Trong thời đại dữ liệu tăng theo cấp số nhân, việc xử lý Big Data nhanh, hiệu quả và linh hoạt là yếu tố sống còn. Google Cloud Dataproc xuất hiện như một ‘người hùng’ mới trong hệ sinh thái đám mây, giúp doanh nghiệp đơn giản hóa hạ tầng và tăng tốc xử lý dữ liệu khổng lồ.
Mục lục
Google Cloud Dataproc là gì?
Google Cloud Dataproc là dịch vụ managed cluster trên Google Cloud, hỗ trợ các framework Big Data phổ biến như Hadoop, Spark, Flink, Hive, Pig, Presto… Người dùng có thể khởi tạo cluster trong vài phút, tự điều chỉnh cấu hình, và xử lý dữ liệu lớn (ETL, batch, stream, ML) mà không cần lo về quản trị hạ tầng
Điểm nổi bật:
- Autoscaling: tự mở rộng số node khi cần
- Auto‑shutdown: tắt cluster tự động sau khi xử lý xong
- Tính phí theo giây sử dụng vCPU, hỗ trợ cả Preemptible để giảm chi phí
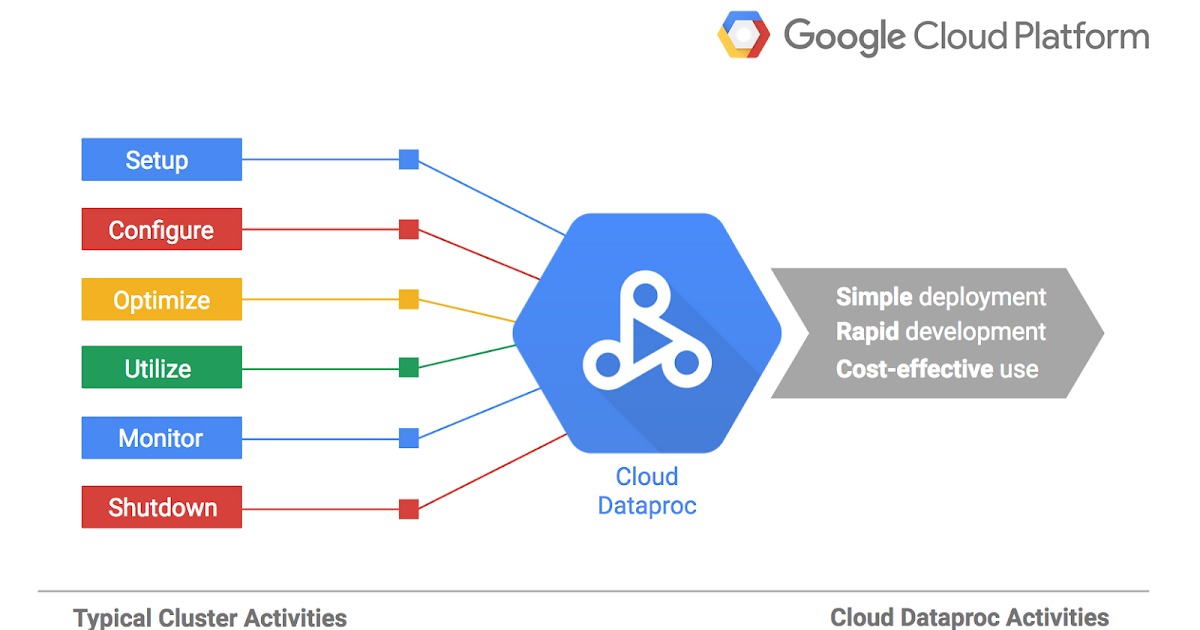
Các thành phần chính trong Dataproc
Hỗ trợ đa framework Big Data
- Tích hợp sẵn Spark, Hadoop, Hive, Pig, Flink… và hơn 30 thành phần mã nguồn mở
Triển khai siêu nhanh
- Cluster sẵn sàng dưới 90 giây, rút ngắn thời gian chờ thể hiện nhanh chóng
Tích hợp Google Cloud toàn diện
- Liên kết dễ dàng với BigQuery, Cloud Storage, Vertex AI…
- Dễ dàng xây dựng pipeline end‑to‑end từ ETL đến AI
Quản lý – bảo mật tự động
- Logging và monitoring qua Stackdriver
- Bảo mật mạnh: mã hóa data‑at‑rest, Kerberos authentication
Xử lý nhiều loại workload
- Từ batch đến streaming, ML — một nền tảng duy nhất, đa năng
5 mẫu Workflow template “chuẩn” Dataproc
| Template | Mục đích | Ưu/nhược điểm |
| Managed Cluster | Tạo – chạy – xóa cluster tự động | Tiết kiệm, phù hợp job định kỳ |
| Cluster Selector | Chọn cluster đang chạy theo label | Tiết kiệm startup, hiệu quả production |
| Inline Workflow | Thực thi trực tiếp qua API/CLI | Nhanh chóng, phù hợp testing/ad‑hoc |
| Parameterized Workflow | Truyền tham số vào workflow | Dễ tái sử dụng, linh hoạt theo môi trường |
| Pre‑built Workflow | Template sẵn cho ETL, log, ML | Triển khai nhanh, tùy chỉnh dễ dàng |
Ưu điểm nổi bật của Google Dataproc
Ưu điểm:
- Cluster quản lý toàn phần, deploy nhanh gọn
- Mở rộng linh hoạt ngay khi cần
- Giao diện trực quan + CLI tiện dụng
- Luôn được cập nhật Hadoop/Spark mới nhất
Hạn chế:
- Cần kiến thức chuyên sâu Hadoop/Spark & DevOps
- Chưa thể “pause” cluster – phải xóa mới dừng
- Khó thay đổi máy ảo sau khi tạo cluster
- Autoscaling không hỗ trợ Spark Structured Streaming
- Với workload nhỏ, serverless (Dataflow, BigQuery) có thể tối ưu hơn
Chi phí & cách tối ưu
- Phí Dataproc vCPU‑giờ: ~$0.01/vCPU‑giờ, tính theo giây (tối thiểu 1 phút)
- Ví dụ: cluster 24 vCPU chạy 2h ≈ 0.48 USD (chưa bao gồm VM, storage…)
Cách tiết kiệm:
- Dùng Preemptible VMs cho worker
- Tự động tạo/xóa cluster theo lịch
- Điều chỉnh respources qua policy autoscaling
- Chọn image version phù hợp
- Kết hợp Dataproc Serverless cho job batch
5 kịch bản sử dụng tiêu biểu
- Automated ETL theo lịch: Cloud Scheduler + Workflow chạy báo cáo doanh thu tự động. Tiết kiệm ~70% thời gian vận hành
- Phân tích SQL với Hive & Cloud SQL: Hệ thống tài chính xử lý triệu giao dịch, tăng hiệu suất ~40%
- Custom Image cho ML: Cluster sẵn thư viện như TensorFlow – giảm từ 30 phút xuống 2 phút
- Initialization Actions: Script tự chạy khi tạo cluster (cài đặt Prometheus, mount dữ liệu…)
- Apache Beam đa engine: Code một lần chạy được cả Dataproc và Dataflow, giảm 60% thời gian dev
Google Cloud Dataproc là giải pháp hàng đầu cho xử lý Big Data trên nền GCP: nhanh – mạnh – tiết kiệm. Với tính năng tự động hóa, tích hợp sâu rộng và quản lý cluster linh hoạt, bạn có thể tối ưu đến 50% chi phí so với triển khai on‑premise
Bạn muốn đăng ký, triển khai hoặc so sánh Dataproc với Dataflow/BigQuery? Nhân Hòa – Partner Google Cloud tại Việt Nam – sẵn sàng tư vấn và hỗ trợ 24/7. Nhấn ngay để nhận tư vấn miễn phí!










")


")
")

